Connections

M&E Journal: Clear the Hurdles to Descriptive Metadata
Story Highlights
By Corinne Whitney, Director of Content Services, Crawford Media Services
Most content owners have recognized the need for descriptive metadata. Taking the first steps toward writing metadata is a daunting task, however. What metadata will be most useful? How should it be formalized for consistency? How to ensure it will be compatible with DAM systems? Who is available to write it with the correct understanding of the content? How much will it cost? How long will it take? How should new metadata be created as new content enters the collection? Together, these questions concerning metadata and digital asset management often lead to “analysis paralysis.”
Common assumptions about metadata continue to surface as organizations try to answer these questions. Because these assumptions halt (and often eliminate) progress, it is a worthwhile endeavor to counter them with legitimate challenges.
ASSUMPTION: Metadata must be addressed within the context of an entire DAM solution. Metadata must be delivered into a DAM system as it is written, or even written within an existing DAM system. The DAM schema must be set and the metadata must be written to that schema. Conversely, the DAM system is not really useful until full metadata is written for all of the assets.
Finding the perfect DAM, developing the perfect schema, identifying subject matter experts (SMEs) controlling labor costs, and avoiding a long time to market are all obstacles that can make progress glacially slow. Addressing metadata needs before, during, and after this process is always a beneficial step that will garner a long-term ROI. On the other hand, the cost of inactivity can be significant.
It is rarely wise to develop a fully realized DAM solution before wading into the process of cataloguing the assets. You simply don’t know what you don’t know, and you probably don’t know enough. Most collections consist of thousands of assets and most of those assets have not been reviewed since their original production. It is better to take a tiered approach. Beginning the process of cataloguing assets will provide a familiarity with the collection that is necessary for two reasons.
First, it will tell you how your assets might need to be grouped. Whether it is by subject matter, quality, chronology, target markets, or other unexpected criteria that you will discover, it is much better to let your assets tell you how they should be grouped than to use theoretical categories. Second, it will provide insight into the true scope of your project. This will help you to identify the correct resources you will need for writing the metadata and will give you realistic expectations about time and cost.
Gathering initial (Tier 1) metadata on your collections is a useful endeavor, even if you do not yet have a master or “final” schema in place. Start with your most-used search terms and an internal taxonomy, then get an objective look at your approach. Metadata that is created outside of a DAM system usually can be imported later—and if your DAM can’t do that, keep looking.
There should be no need to wait for technology implementation or integration — metadata should transfer to other and future DAM solutions. Cataloging collections with human context is a sound investment, regardless of a chosen DAM, because metadata is inherently DAM-agnostic. Some metadata is better than no metadata, and when cataloging begins in earnest that information will help tremendously, and can save time and money spent on completing later fields.
This Tier 1 pass should have a very basic, unambiguous schema that does not require great insight or subtle judgement calls so it can be collected inexpensively and at a fast pace. It should capture basic information about content such as product or program, episode or title, and it should also gather basic format metadata if that is not already known. This would include information such as run-time, tape or file format, and date. This initial cataloging will inform both the development of the master schema and the rollout of the DAM.
ASSUMPTION: Once metadata is written, the project is complete. We must do it once and get it right. The organization can’t afford to revisit the metadata. We will get this approved in the budget one time and be done.
While this line of thinking is appropriate for the initial phase of creating metadata, it is wrong not to plan for additions and revisions. Metadata is ever-evolving, not evergreen. Regular cultivation of metadata will make both the metadata and the content itself more continually useful in the long term, and will prepare those assets for future use. For instance, an automotive manufacturer may eventually tag older vehicle models as vintage, retro or classic. This can happen long after initial and thorough metadata is written for all elements pertaining to production, advertising, distribution and sales. In most archival collections, additional metadata has been necessary in recent years to maximize the cost benefit for new uses and outlets, such as streaming delivery or stock footage.
ASSUMPTION: Our assets and metadata are too industry / company / brand- specific for outsiders to accurately tag. No one from outside our organization would ever have the knowledge or context to properly tag our content. Only our editors/producers/product specialists/scientists/engineers/etc. can do it correctly.
This can be a self-defeating assumption. Most internal SMEs have mission-critical roles in the organization. The very knowledge that makes them a SME also makes them unavailable for writing metadata. Meanwhile many organizations cannot justify employing and training metadata entry specialists in their yearly budgets. It’s a catch-22.
Luckily, metadata writing is an increasingly available skill set for independent contractors who have learned to parse information. The U.S. has a wealth of knowledge workers seeking schedule flexibility and off-site/remote connectivity. The newly dubbed “on-demand economy” model embraces and accommodates this market trend. In fact, highly skilled professionals now expect the ability to work remotely and on project-based tasks. Business strategists and global consulting companies alike have announced that this highly digital and modern approach is upon us, but many companies lack the bandwidth to onboard a contingent workforce.
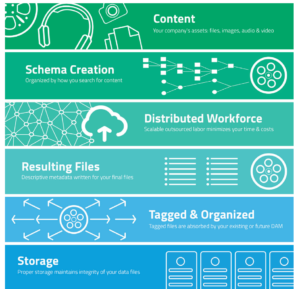 Providing an onshore distributed workforce with knowledge and information unique to a collection (in order to meet an organization’s specific needs) is no small feat but, to provide the most accurate and consistent metadata, it is possible.
Providing an onshore distributed workforce with knowledge and information unique to a collection (in order to meet an organization’s specific needs) is no small feat but, to provide the most accurate and consistent metadata, it is possible.
An incremental approach – with properly trained and supervised, outsourced labor – can get content into circulation faster and provide insights resulting in a metadata strategy that is ultimately more efficient and better targeted. The outsourced labor solution can be developed directly by your organization or developed and provided by an outsourced labor contractor. The key is to provide the contingent workforce with appropriate guidance and to simplify the tasks.
This is where the incremental approach will pay off. When working on a large collection, any metadata writer will encounter content that transcends their knowledge unless the collection is curated to direct the correct content to the writer. It is a rare person who has equal knowledge of heavy metal, hip hop and country music; or automotive engineering, racing and brand management.
By steering the correct content to the correct writers, it is possible to not only recruit writers with an affinity for the content, but to train the writers for the context and specific terms that are relevant to the organization. This is augmented with dropdown lists, predictive text, “look books” and other reference materials in the writing tools that reinforce the writer’s training, provide consistency and reduce opportunities for mistakes.
The highest and most complex levels of metadata writing may be left to internal experts, but properly managed contract labor can provide tagging of typical collections with a margin of error that equals or improves upon in-house labor that has neither the time nor focus for writing metadata.
Clearing the hurdles to creating descriptive metadata requires a fresh look at old assumptions. Metadata does exist independent of a DAM. It is better to add metadata sooner than later. Solely utilizing internal SMEs is ultimately slower and more expensive than utilizing outsourced labor. Technology has created more ways for a flexible workforce to engage and “ramp-up” their knowledge base on subjects in the short term, and there are more tools available than ever to leverage that population. A baseline of solid metadata will position your assets and your organization for adopting new technologies, and better placement within monetizable platforms now and in the future.
—-
Click here to translate this article
Click here to download the complete .PDF version of this article
Click here to download the entire Spring 2017 M&E Journal








